
July 2016 Issue
Read, Comment and Enjoy!
Join Translation Journal
Click on the Subscribe button below to receive regular updates.
Terminology variation and foreign language hegemony: The case of the Arabic-speaking North African countries
- Details
- Written by Fawzi Hamed
Abstract
This study is concerned with examining the linguistic situation in the Arab-North African countries and its impact on terminology policy. It is based on the hypothesis that one of the main factors behind the phenomenon of term variation and term formation is the influence of foreign languages, mainly English and French. The hegemony of foreign languages affects technical term formation and use. To test this hypothesis, the study examines terminological variation in context. The study uses a corpus-based approach to terminology, which supports the observation of term variation and allows comparison of Arabic texts from the specialized subject field of computers and the Internet so as to extract valuable information about terminology policy. The focus is primarily on orthography (e.g., spelling variations, vocalization, etc.), morphology (e.g., variations related to inflectional phenomena such as number and gender and derivational variations), lexicon (e.g., synonyms used interchangeably), phonological variations, and abbreviations.
Keywords: Arabic terminology; term variation; terminology policy; language hegemony; corpus.
1. Introduction
The Arab-North African countries (ANAC; i.e., Egypt, Libya, Tunisia, Algeria and Morocco) have long been mistakenly characterized by the omnipresence of Arabic, or of so-called Modern Standard Arabic (MSA). The ANAC region is considered today to be perhaps the most multilingual region in the Arab World (AW). This consists, partly due to the hegemony of foreign languages, mainly French and English. Although the entire ANAC is Arabic-speaking and MSA is the only official language, the current sociolinguistic situation is vastly more complex and dynamic than in other Arabic regions such as the Arabian Gulf and the Middle East, simply due to the linguistic diversity of the region. The conflict of prestige and power between the two colonial languages in the region English and French is an increasingly noted phenomenon. The continued hegemony of French as a tool for modernization and development and the growing demand for English as a medium for modern science, technology and economic development have resulted in the phenomenon of discrepancy and inconsistency of terminology across the region.
The competition between English and French has created two terminological sources: French-oriented source in Morocco, Algeria, Tunisia and Mauritania; and English-oriented source in Libya, Egypt and almost all of the rest of the AW. These two foreign language oriented-regions are distinct not only linguistically, but also culturally, socially and economically as a consequence of a long history of British and French colonization. This means that translators and technical writers are apt to accept or adopt at least one of two Arabic equivalents or terms for some foreign technical terms in accordance with their dominant foreign languages, either French or English. French-competent translators might adopt one Arabic equivalent from French and English-competent translators might adopt a different Arabic equivalent from English.
2. The Role and Status of French
The use of Arabic was well established all over the region until contested by French colonialism. Arabic was the only written language before colonization imposed French, written and spoken, and it assumed an official status. In fact, the presence of French in the region is not a one-time event. It represents a continuing policy that began with the French conquest of Algeria in 1827. Later, France began to assert its influence on the neighboring countries of Tunisia and Morocco, and in 1884 Tunisia officially became a French protectorate. Immediately after colonizing the whole region, France attempted to change the political and cultural tradition of the people by increasing the spread of French at the cost of MSA and the individual dialects (Talmoudi, 1984). It also tried to create a territory almost dependent on France by imposing the French language and rejecting everything associated with other languages and cultures. This strategy was best summed up by Gordon (1964, p. 7), who states that "When the Portuguese colonized, they built churches; when the British colonized, they built trading stations; when the French colonized, they built schools". Algeria offers concrete evidence for this tendency. By 1848 it formally became a part of France, and the French language became the official language. Later, French became the official language of the other two countries in the region (Morocco and Tunisia) and the only language allowed to be taught in schools. Arabic "was completely ousted by the language of the colonizer" (Van Mol, 2003, p. 26). It was later, in 1938, declared in Morocco a foreign language by decree (Holt, 1994).
Therefore, French language retains a very strong physical presence in Tunisia, Algeria and Morocco. Today, the three countries rank among the ten countries in the world with the most French speakers (État de la Francophonie dans le monde 2004–2006), particularly in the case of Algeria and Morocco, where the status of French is far from that of a mere foreign language. Benrabah, an Algerian linguist, states that "the situation of French language in Algeria is unquestionably unique in the world" (cited in Aitsiselmi and Merley, 2008, p. 9) because of its widespread use in various domains. In most cases, French is the language of administration, education and a large scope of business and the economy. Despite the fact that these countries gained their independence fifty years ago, French still plays a very significant role in the region. It has continued to occupy an important position because it is seen as the language of social and professional success. "There is a clearly perceived link between speaking French and achieving success: people in power, be it in politics, the army, business, banking, public and private companies, always have a good command of French" (Benrabah, 2007, p. 202). Many business activities, even simple ones, are still conducted using French.
The influence of French can also be observed in the education systems. In spite of all efforts to arabize higher education since independence from France, the university sector has remained far from fully arabized; many scientific fields of knowledge in universities and colleges are still taught in French. These include, but are not limited to, medicine, pharmacy, engineering, nursing, physics, chemistry, biology, mathematics, and administrative sciences.
Not surprisingly, French currently holds the leading position among the languages that have influenced Arabic in the ANAC region. This influence can be clearly seen in people's dialects, which are often mixed in with French in everyday conversation to form a dialect often informally called Frarabic. Frarabic is "An amalgam of the French and Arabic languages, sometimes producing very distorted sounds. It relates mainly to code-switching in mid-sentence or a single French word that has been given Arabic intonation" (Urban Dictionary, www.urbandictionary.com). Frarabic is often used in Francophone Arab countries such as Morocco, Tunisia and Algeria. In Tunisia, for instance, the two greetings of Arabic السلام عليكم assalamualaikum (equivalent to hello in English) and French ça va are often mixed as Asslama, ca va. In addition, شكراً shukran and merci (thank you in Arabic and French) are used interchangeably. Similarly in Algeria, according to Aitisiselmi and Marley (2008, p. 204), the use of mixed code is more marked especially when the subject is culture-specific; "there is frequent use of Arabic terms which signal a religious reality for Algerian listeners that cannot be adequately expressed in French". For example, the Arabic words ربي rebbi my God and الحمد لله il-hamdullah thank God are often used in expressions such as on réussira b-rebbi (we'll succeed, God willing) and il se porte bien maintenant, il-hamdoullah (he is feeling better now, thank God).
3. The Role and the Status of English
The situation in Egypt and Libya is quite different from in Tunisia, Algeria and Morocco. Although Egypt was conquered by the French from 1798 to 1801 and French was the first major European language introduced to Egyptians during Napoleon Bonaparte's campaign, French has had little impact on the dominance of Arabic among Egyptians, although it was favored as a foreign language among other choices such as Turkish, Persian and Italian. This foreign language situation changed after the British occupation began in the 1880s, particularly at the beginning of the First World War. The British made concerted efforts at widening the influence of English instruction in Egypt's schools because, as Tignor (2011) puts it, they saw Arabic as 'too imprecise' to be a language of science. Therefore, all secondary school and university subjects, except for Arabic and mathematics, were taught in English. This policy continued until the British administrator, Lord Cromer, reversed the stance of the education bureaucracy and the repression of Arabic in schools in 1905 (Schaub, 2000).
In Egypt today, English is a mandatory subject that is first introduced at the preparatory level, and it is the language of instruction in most faculties in national universities. Jarrar and Massialas (1992) observe that many of the textbooks and reference materials are in English, and in medicine and engineering, all of the texts and many of the lectures are in English. English also plays a significant role in the popular culture of Egypt; it is used alongside Arabic in road signs and the names of shops and cafés. Printed materials in places such as hotels, restaurants, banks, airports, travel agencies and post offices are usually written both in English and Arabic. Brand names, such as KFC, Subway, and Starbucks, are written only in English and without any kind of translation. In fact, the tourism industry, which is one of the most important sectors and the largest source of hard-currency revenue in Egypt, may be considered the main factor behind the dramatic widespread study and use of English. Elkhatib (1984, cited in Shcabaub, 2000) notes that Egyptians, especially if they live in areas frequented by tourists, need to learn English. Merchants and even juice sellers stand to increase profits greatly if they are able to communicate with visitors in English.
Although the use of English in Egypt is increasingly becoming common at both formal and informal levels, Arabic – Egyptian Arabic in particular – is without question the dominant language. It is the language of choice for most Egyptians, not only when they speak in their everyday communication, but also in more formal contexts such as communication in higher education, business and policy.
The discovery of oil in the late 1950s played a major role in the development of the English language in Libya. Major foreign petroleum companies such as Shell, British Petroleum (BP), and Exxon Mobile rushed to Libya for exploration and drilling. By the end of 1977, there were forty-two foreign companies conducting exploratory and drilling activities in Libya (Hassan 2009 http://sepmstrata.org/Libya-Hassan/Petroleum-History-Libya.html). As a result, the oil and gas industry has increasingly become the main Libyan job market where English is the means of communication between Libyans and native and non-native speakers of English alike. Upon entering the industry, all workers are required to have at least a basic knowledge of English for effective and safe operations (National Oil Corporation 2009, http://en.noclibya.com.ly/). This, in turn, brings a very significant requirement for English language learning and training, particularly with regard to technical operations. English is, therefore, seen not only as the key to securing a better job in the Libyan oil sector, but also as the means of developing social, economic, commercial and scientific relations with non-Arabic companies and individuals from within Libya and internationally.
However, the status of English has undergone tremendous changes in the past two decades for purely political reasons. Influenced by Gamil Abdul Nasser's revolution in Egypt in 1952, Libya proclaimed a Cultural Revolution in 1973. There was a move to shift authority from Western-oriented capitalism into a strongly nationalist and socialist country (which was at the time perceived as 'anti-Western'). Thus, everything originating from the West and from the United States and the UK in particular became unacceptable and prohibited, including language, which was regarded as imported culture that had to be rejected. English books, magazines and newspapers and even Western musical instruments were collected and burned in public squares. These measures were extended, according to Maghur (2010), to private schools and foreign centres; several private foreign schools and foreign centres such as the British Council and the American Cultural Institute were shut down. As a result, an acute problem now exists, whereby Libyan schools and universities in general do not have a satisfactory stock of books and other references related to foreign language teaching and learning.
4. Corpus Design and Compilation
The corpora compiled for this study were two 'raw' comparable electronic corpora of original Arabic texts that represent the two foreign-language orientations. Raw corpora means that the texts themselves are compiled ad hoc without any kind of tags or markup . The first corpus (C1) represents the French-language orientation in Morocco, Algeria and Tunisia, and the second (C2) represents the English-language orientation that exists in Libya, Egypt and almost all of the rest of the AW. The following are the main features of the corpora:
- To limit confounding variables, the two representative corpora are intended to be balanced and comparable in terms of text topic, number of texts and words, date of publication, target readership, etc. Most importantly, the eligible texts cover the same subject field (computers and the Internet) from different sources in all the ANAC countries. The two corpora are comparable in terms of total number of tokens (words). C1 has a slightly higher number of tokens than C2. 250,360 tokens were obtained and used for the word list for C1, whereas 246,624 tokens were obtained for C2 and used for the word list. C1 and C2 were matched on the basis of the total number of words but not on the total number of texts included. In other words, the total number of words per corpus was equaled by including more texts in cases where one corpus has fewer words than the other (see Appendix I). This may explain the difference between the two corpora in terms of the total number of texts included (33 texts for C1 and 30 texts for C2). It also justifies the slight difference in numbers of sentences (12,583 sentences in C1 and 11,287 sentences in C2).
- The compiled documents belong to institutions and organizations from different countries in the region, namely: university, company and organization websites, formal online technical support, IT magazines and periodicals, as well as computer and Internet websites and journals. This was performed by using Google "Advanced Search" Regional Function (http://www.google.com). The search was also widened to consider the 'Internet site's country domain' like ',ly' for Libya, '.eg' for Egypt, '.dz' for Algeria, '.tn' for Tunisia and '.ma' for Morocco. The question that can be raised here, however, is how well Google differentiates the country or region from which a web page originates. Google explains that
We rely largely on the site's country domain (.ca, .de, etc.). If an international domain (.com, .org, .edu, etc.) has been used, we'll rely on several signals, including IP address, location information on the page, links to the page, and any relevant information from Google Places. (https://support.google.com/ webmasters/answer/62399?hl=en)
- Resources are presented on the web in three basic presentation forms: HTML and XML text, and PDF. Documents in PDF, XML and HTML format were located in MS Word by means of copy and paste before being converted into plain text format and saved as Unicode. This is a critical feature in this case for two reasons. First, the Word Smith Corpus Tool (WST) can index and retrieve Arabic texts only in plain text format (*.txt). Second, Unicode is an encoding scheme that allows the use of the full variety of scripts for human languages, including Arabic, which is not accommodated by earlier encoding schemes. In the case of HTML and XML format, the procedure for including the material in the corpora is 'copy and paste,' and in the case of PDF, it involves downloading and saving the material in text format. Although converting these texts' formats into plain text format is quite straightforward, Arabic texts require special handling during the conversion of the texts from the PDF, HTML, DOC or other file formats into the .txt format for making the texts processable by WST.
4.1. Processing the Corpora
Once the corpora had been compiled, a stop list with function words for both corpora was created to avoid counting high frequency functional words. The stop list included 92 words extracted from the first 100 functional words in the initial frequency list. It should be noted that the stop list did not include all function words, but only the ones that have had the highest frequency of occurrences in each corpora. The words included in the stop list are listed in Appendix II. This list was used for the two corpora, but each corpus was processed separately. The following screenshot (Figure 1) shows the word list before the generation of the stop list. It is evident that function words such as في fee in, من men from and و waw and have the highest frequency of occurrences in the word list (2.809, 2.309 and 1.538 respectively).
4.2. Term Inclusion
After the creation of the stop list, it was uploaded into WST in order to produce a list of content words in each corpus. Once function and unwanted words were excluded by means of the stop list and the most frequent content words in the two corpora were identified, specialized single-word and multi-word terms for computers and the Internet were manually selected from the created word list. The Wordlist function in WST was used to obtain the frequency of the words in each corpus. The selection of terms was made according to the following criteria:
(1) Common terms from information technology (i.e., terms that occur more frequently than others), which could be used by both specialized and non-specialized users;
(2) Terms coined by different means of term formation in Arabic, such as translation, derivation, and borrowing; and
(3) Terms that potentially have many synonyms. For the sake of simplicity, I concentrated only on specific terms for which there is no established standard equivalent or an accepted lexical unit in MSA and that thus pose a source of difficulty for Arabic technical writers and translators (e.g., new computer and Internet terms that are too novel to be listed in Arabic glossaries and dictionaries).
4.3. Term Exclusion (Lemmatization)
At first glance at the term list, I noticed the problem of the lack of stemming (lemmatization ), i.e., the lists include individual entries for both the base forms and for their inflectional forms. For example, the term شبكة network appeared both in singular as شبكة network and plural شبكات networks forms in the list. One reason for this problem is the highly derivational and inflectional nature of Arabic language , coupled with the absence of any reliable lemmatization utility for the Arabic language.
WST was used to lemmatize inflectional words. For example, in Figure 2, the terms التكنولوجيا the technology with the definite article ال the (freq. 166) and تكنولوجيا technology without the definite article (freq. 89) were lemmatized together (no. 22), which thus accounted for 255 occurrences. The term تكنولوجيا technology retained its original position, but it had been reduced to zero occurrence in the lemmatization procedure . The same process was performed on the term شبكة network and الشبكة the network. Several terms in the same lemma were left in their separate entries. For example, the verb يتصفح yatasafah to browse and the noun متصفح motasafih browser are left in separate entries, even though they are derived from the same base, because they are different parts of speech.
The corpora files were then used to manually identify and compare synonyms to determine whether there is any term variation, regardless of whether the variation occurs within the boundaries of one corpus or in separate corpora. Terms are considered synonyms if they have the same meaning and are assumed to represent the same concept. For example, the terms (برمجة عبر المنصات, البرمجة المتعددة المنصات, ' البرمجة متعدية المنصات) are synonyms and equivalents to the English term cross platform. The focus was primarily on orthography (e.g., spelling variations, vocalization, etc.), morphology (e.g., variations related to inflectional phenomena such as number and gender and derivational variations), lexicon (e.g., synonyms used interchangeably), phonological variations, and abbreviations.
4.3. Terminological Analysis
This phase started with gaining an overall view of the most frequent terms in C1 and C2 by creating key term lists, which included terms that had higher frequencies of occurrence in the original list. WST defines the lists on the basis of single lexical units by recognizing characters between spaces. In many circumstances, however, this identification is not accurate, as many technical terms are made up of more than one word. For example, the term جهاز غير متزامن jihaz ghayr mutazamin asynchronous device is considered one terminological unit consisting of two words in English asynchronous and device. Separating the words leads to a change in term meaning. In Arabic, the problem is more complicated, because this term contains three words, i., e., جهاز jihaz device, غير ghayr not and متزامن mutazamin synchronous. WST treats these three words as three separate units, each has its own frequency occurrences.
To solve this problem, WST Concordance was used . WST concordance made it possible to browse the corpora and visualize the searched terms in their original contexts. This tool enabled me to determine whether the term in the lists was used as a single word unit or a multi-word unit by looking at its most frequent neighboring words. The following screenshot is an illustration.
Figure 3 shows the concordance of the occurrences of the term المعلومات alma'lumat information in C1. It lists all the occurrences of the term المعلومات (highlighted in blue by the software) with their collocations (highlighted in red), such as ابناك المعلومات abnak alma'lumat information banks, استرجاع المعلومات isterja' alma'lumat information retrieval, and أنظمة المعلومات andhmat alma'lumat information systems. However, this output is not in the right order due to bi-directional nature of Arabic script. The occurrences of المعلومات information are displayed at the beginning of the line, whereas their collocations, such as the word ابناك banks in line 3 and استرجاع isterja' retrieval in line 8, are displayed at the end. It seems that WST concordance does not take the bi-directional nature of Arabic into account when displaying results. Admittedly, when I double-clicked on one of the concordance lines in order to see the source text, the ordering issue disappeared and words were shown in the right order for some unknown reason, but it seems that WST retrieved and showed the texts in its original txt files, which were already saved as Unicode.
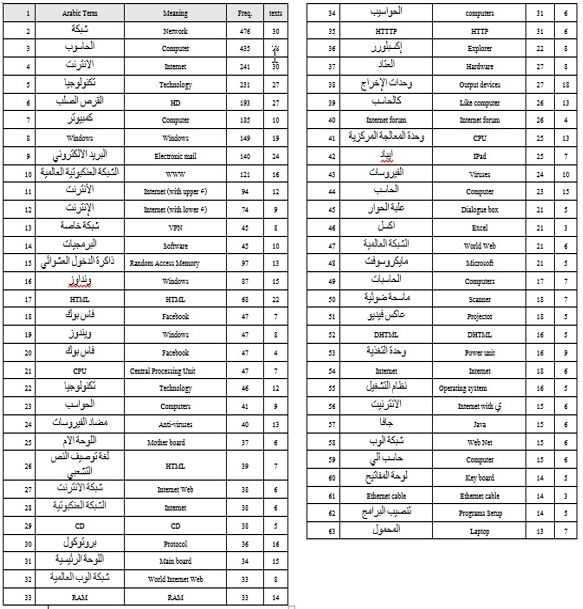
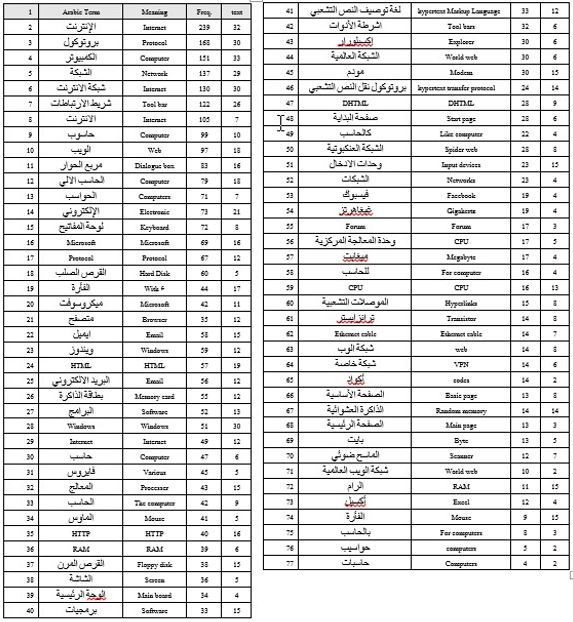
Once all term occurrences in C1 and C2 were identified, the absolute frequency of each term was then calculated for each corpus. The two corpora were treated separately so as to generate a distinct term list for each one. In order to avoid analyzing a very large number of terms, only terms that were directly related to the domain of computers and the Internet and that had a frequency of 10 or higher were selected as key terms for analysis. Full listings of the most common terms that occurred more than 10 times can be found in Appendix III for C1 and Appendix IV for C2. C1 yielded a key term list of 63 terms, whereas the list for C2 was 77 terms. Only terms recorded in these two final lists were taken into account in the final analysis.
After collecting all the key terms, concordance analysis was carried out. Terms in the C1 list were inspected and compared with those identified in C2. Cross-terminological aligned tables were compiled by consistently linking terms in one corpus with their synonyms elsewhere. The objective here was to visualize terminological relationships between terms from different regions so as to carefully examine, describe and classify the specific objects of this comparison. Comprehensive reference tables were then worked out for variations or similarities that were found. The tables included a classification of terms according to the type of terminological variation—for example, terminological variation from linguistic perspectives such as orthographic variation (ORV), lexical variation (LV), morphological variation (MV) and abbreviation (AV); terminological variation from a colonial perspective (i.e., terms based on choices made in accordance with the dominant foreign language, either French or English); and variation from a geopolitical perspective (i.e., terms based on relevant communication problems and the current concern of Arab countries to build up their individual political identity).
5. Results and Discussion
Term variation is a natural phenomenon which, far from being avoided, is widespread in specialized discourse (Freixa 2006) and which occurs as part of the terminology formation process. In theory, terms should be mono-referential (Spasic el al., 2003, p. 245), i.e., there should be a correspondence between concepts, with one term for one concept. The observation of the corpora in this study, however, shows that most Arabic terms are homographic, which means that the same concept corresponds to many terms. Terminological variations that appear in the study corpora can be roughly classified into orthographical variations, morphological variations, lexical variations, abbreviations and neologisms.
5.1. Orthographic Variation
Due to the influence of the French language on speakers from Morocco, Algeria and Tunisia, writers often adapt French phonological features by the insertion of certain sounds; thus the vowel (ي) ya is added to the loan term 'انترنت' Internet. In the corpus collected from Morocco, Algeria and Tunisia (C1), the placement of the long vowel (ي) is a noticeable phenomenon. Analysis reveals that the addition of the long vowel (ي) corresponds to the French pronunciation of the term. Writers from this region prefer to infix (ي) in the term انترنت, while Egyptians and Libyans do not, because this shift does not reflect English pronunciation. The frequency of the term انترنت antrnt without (ي) in C1 is (nil), and in C2 it is 123, whereas the frequency of the term انترنيت antrnyt with (ي) between the last two characters ن and ت is 318 in C1 and (nil) in C2. The frequency of انترنات antrnaat with an extra أ alif between ن and the final ت is 134 in C1 and (nil) in C2. Furthermore, the term مودم modem has been adopted with the (ي) vowel inserted in the root to correspond in sound to French. It is spelled in C1 as موديم modaïm (frequency 15) and in C2 as مودم modem (frequency 30). This difference between the two terms (انترنت internet and مودم modem) can be explained by proposing that each represents a different foreign-language reference. The long vowel (ي) in terms such as انترنيت intrnyt and موديم modaïm and the long vowel (ا) in انترنات antrnaat are infixed as the result of conscious or unconscious assimilation and emulation of the French pronunciation of the two terms, which is different from how the same terms are pronounced in English. Similarly, the phoneme (ق) in قوقل gugle Google, which occurred 2 times in C1 and 30 times in C2, is replaced with (غ) in غوغل Google ghoghl in C1 (12 occurrences in C1 and 0 occurrence in C2) in accordance with speech features of C1 and C2 speaking communities.
5.2. Lexical Variation
The influence of French on Arabic was apparent during the first phase of collecting texts for C1. Websites from which texts were used for the components of C1 were characterized by the excessive use of French terms, even though these websites were published in Arabic. This was not the case with websites used for collecting C2 data. This point is also recognized by Zakaria Sahnnon (Arab Newspaper, 8 June 2008), who maintains that
...وبتصفح جل المواقع المغربية, سنلاحظ أن غالبيتها تستعمل اللغة الفرنسية, كما أنه بنقصها الإبداع والجديد حيث يلاحظ علي هذه المواقع تكرار المعلومات الموجودة في المواقع الأخرى, بسبب الاعتماد علي المواقع الأجنبية (وكالات الأنباء, مراكز الدراسات...الخ)
...When surfing Maghreb sites, we will notice that the majority of them use French. Many of them lack creativity, and they update and repeat information found in other sites because of their dependency on foreign sites (e.g., news agencies, research centers, etc.). (Translation by the author)
Given this reliance on foreign sources, there is an ever-present influence of foreign terms and phrasing on Arabic writers. It is possible to explain the lexical variations between the two sides of the ANAC region by proposing that each represents a different foreign language reference.
The influence of French on the lexical level through literal translation of certain terms is apparent. Table 2 illustrates some of these variations. In the first example, the term العتاد al'atad (which literally means materials and is used as an equivalent for the English term hardware) is a literal translation of the French word matériel, which is commonly used in French as an equivalent for the word hardware. The term العتاد al'atad occurred 27 times in C1, whereas its synonym اجهزة aẖhïza occurred 33 times in C2.
This attitude may be explained by several factors, including the increased prominence of French as a medium for modern science and technology, the current heavy dependence of economic and educational activities in this part of the ANAC region on France, and the prestigious status assigned to French as the language of social superiority and professional success. Consequently, Arabic technical language in the ANAC region has absorbed many terms from French in order to meet its technical communication needs.
5.3. Morphological Variation
The term حاسب hasïb computer and its derivations are exclusively found in C2, whereas رتابة rattaba (literally meaning ordering things) is found only in C1, where French is the dominant foreign language. It is noteworthy that rendering the concept computer as رتابة rattaba returns to the original French term ordinateur, which – like its Arabic equivalent رتابة rattaba – carries the meaning of ordering things. This variation supports the assumption that each corpus represents a different foreign-language reference.
The direct loan كمبيوتر kumbutr for computer, however, is commonly found throughout the two corpora. This term has a frequency of 185 in 10 texts in C1 and 151 in 10 texts in C2. This high frequency of occurrences might be explained by the fact that this loan is informal and may appear in any kind of communication, either formal or informal, whereas its Arabic equivalent حاسوب hasub is more formal and restricted in standard communications. Furthermore, the universal frequency (i.e., the frequency of the term in the two corpora) (124) reflects the strong influence of foreign languages in general on terminology formation in the AW. It is worth noting that the English word computer has become an international word, as it occurs in several languages with the same or at least similar orthographic or phonemic form (see ISO 12620, 2009). This internationalism occurs as a result of simultaneous direct borrowing and acceptance from one language into another. Internationalisms frequently reflect Latin, Greek or English origins, but other languages, such as Arabic, French, Russian, Chinese and Japanese, have also contributed to the creation of internationalisms (ISO 12620, 2009).
Number and gender are also noticeable phenomena in terminology formation. The Arabic language is characterized by a strong tendency for agreement between elements. In matters of gender and number, these characteristics are expressed by a comprehensive system of affixes and inflections. In Arabic all nouns are classified into masculine or feminine. Feminine gender is often associated with a bound morpheme ﺔ ta marbuta or what is called تاء التأنيث ta al-taneeth 'feminine ta.' Masculine gender, on the other hand, may be indicated with no suffix. For example, the word طابعة printer is a feminine noun, because ta marbota (ﺔ) is attached to the end of the word. The dual is also formed by adding (ان) 'ina' to the end of masculine nouns and (ين) 'yan' to the feminine nouns. The plural is formed by adding (ات) 'at' at the end of nouns. In all cases, the inflections can be irregular, as is the case in English and many other languages. The pattern of the singular noun is dramatically altered in certain cases.
The morpho-syntax of the reference language (French or English in our study) is a significant factor in determining term gender in Arabic. Whether a term is feminine or masculine tends to be affected by the gender of the equivalent foreign term. The use of feminine terms seems to be dependent on foreign language influence. For instance, the use of a feminine noun to refer to the word فأر mouse is more frequent in C1 than its counterpart in C2. فأرة mouse (feminine) occurred 31 times in C1 and nil times in C2, while فأر mouse (masculine) occurred (12) times in C1 and 44 times in C2. Similarly, the feminine term ماسحة ضوئية masiha thu'ya scanner occurred 18 times in C1 and nil times in C2, whereas the masculine term ماسح ضوئي masih thu'y scanner occurred only 4 times in C1 and 12 times in C2.
This indicates that writers in Morocco, Algeria and Tunisia accept the use of the words فأرة mouse and ماسحة ضوئية scanner (feminine), which were coded in C1 based on the assimilation of the French words 'la souris,' and 'ѐchographe' (feminine nouns in French), whereas the low frequency of the feminine words فأرة and ماسحة ضوئية in C2 indicates that they are not regularly used in Egypt and Libya. فأر mouse and ماسح ضوئي scanner (masculine) are more popular than the feminine terms فأرة and ماسحة ضوئية. Furthermore, in many cases this ة or ﺔ 'ta marbuta' that indicates feminine nouns is written as ه or ﻪ ha without the two dots, which makes word retrieval even more difficult. This can be attributed to the fact that the ة or ﺔ 'ta marbuta' is rarely pronounced as ta ة or ﺔ. It is often pronounced as ha ه or ﻪ with or without the two dots.
5.4. Variation and Borrowed Terms
Examination of the study corpora reveals that borrowing is the most frequent technique (among others such as literal translation) used for terminology creation. In C1, 45 borrowed terms have the highest frequency in the field of computers and the Internet. Some terms are not field-specific, for they can be found in other fields (e.g., كارت kart card and كيبل kaïbl cable), while others are specific to the domain of computers and the Internet (e.g., قرص بلو ري qurs blu ry blue ray disc and ملتيميديا multïmdya multimedia). Table 4 shows the most frequently borrowed terms detected in C1, together with their English counterparts in C2.
The values in Table 4 indicate that there is no great difference between C1 and C2 in terms of borrowing from foreign languages in general. The table shows that the term تكنولوجيا tiknuljya technology is the most frequent in C1 (231), whereas in C2 the term بروتوكول brutukul protocol has the highest occurrence (168), followed by كمبيوتر kumbutr computer, which has 185 occurrences in C1 and 151 occurrences in C2. The two borrowed terms سكنر skanr scanner and ماوس maus mouse have also similar frequencies in both corpora. While سكنر occurred 67 times in C1 and 73 times in C2, ماوس occurred 55 times in C1 and 41 times in C2. The biggest difference occurred in the term الكتروني eliktrony electronic, which occurred 158 times in C1 but only 73 times in C2. This indicates that there is a tendency among Arabic writers in general to use borrowed terms although there are established Arabic equivalents for many of these foreign terms. For instance, تقنية taqniya for technology, حاسوب hasub for computer, ماسح ضوئي mash dhui for scanner and فأرة for mouse. The frequency of occurrences of ماسح ضوئي scanner and فأرة mouse in Table 3, for instance, is much lower than the frequency of occurrences of the loans سكنر scanner and فأرة mouse in Table 4.
Lexical variations may occur as a result of borrowing from different sources. Table 5 shows variations in three borrowed terms. In the first example, the term بورتابل burtabl laptop is a direct loan of the French term 'portatif,' which means laptop, while the term لاب توب labtub is a direct loan of the English term laptop. In the second example, the quality of the vowel (whether long vowel in كيبل kaïbl cable or short vowel in كابل kabl) is determined by way of approximation rather than by Arabic phonological criteria. The foreign vowels in cable were trans-positioned in Arabic كيبل kaïbl and كابل kabl. The term network typology was also used in C1 as طبولوجيا الشبكة ṫbuluẖya aṣabaka without the vowel (و), whereas طوبولوجيا الشبكة ṫubluẖya aṣabaka with the vowel (و) was used in C2. The reason for this variation is also related to the trans-position of the short and long vowels in both English and French. The و in طوبولوجيا الشبكة ṫubluẖya aṣabaka was inserted to represent the long vowel /ai/ in the original English term typology /tai'paldәdӡi/, whereas the omission of that و in طبولوجيا الشبكة ṫbuluẖya aṣabaka was made to transpose the short vowel in the original French term typologie. In other words, writers tend to spell the loaned term in a recognizable approximation of its original source, either English or French.
5.5. Phonological Variations in Borrowed Terms
As noted above, writers from the two parts of the ANAC region vary in their use of borrowed terms. The diversity in the occurrence of loans appears to take place on the phonological level by maintaining the source language pronunciation in the borrowed term. Writers adopt loans according to whether their linguistic source is French or English. It seems that writers' background knowledge of either French or English increases the approximation to the original French or English pronunciation of terms. The borrowed term 'وب' web, for instance, takes different forms when used as a loan in the two corpora. It is وب wab in C2 and ويب wïb in C1 with additional (ي) infixed. Examples that show the impact of foreign language phonology are introduced in Table 6.
Table 6 shows the spelling variations for six terms. For the first, the spelling موديم mudïm was used 15 times in C1, and مودم mudm was used 30 times in C2. For the second, ويب wïb web was used 15 times in C2, whereas وب wab was used 14 times in C2. For the third term email, إيميل ïmayl was used many more times in C2 than إيمال ïmal in C1—58 times for the former and only 11 times for the latter. This is because إيميل ïmayl is more popular throughout the AW and commonly used than إيمال ïmal. For the last term, virus, the spelling فيروس faïrus was used 40 times in C1, while the spelling فايروس fïyrus was used 45 times in C2, showing that both spellings were used with similar frequencies in the two corpora. This means that the two spelling variations have similar popularity in the ANAC region. Two important points should be considered here. First, some of the terms have an Arabic equivalent, as indicated in the second column from left (meaning). For example, web has the Arabic equivalent شبكة ṣabaka, yet the French-derived word ويب wïb is widespread in C1 and the English-derived term وب web is used in C2. Borrowed terms such as فيروس faïrus virus, إيميل ïmayl email and مودم mudïm modem are also used even though they have Arabic equivalents (جرثومة ẖrthuma virus, بريد الكتروني barïd alktruny email, and مرسل رقمي mursl raqamy modem respectively). Secondly, some of these terms do not have an Arabic equivalent, and the borrowed word is the only existing word in the language. ترانزيستو tranzïstur transistor in Table 6 is an example. Note that in the case of the term فيروس /فايروس virus, the sound /v/, which does not exist in the Arabic phonological system, is often substituted by its nearest homorganic Arabic sound (ف /f/) in order to assimilate foreign sounds to Arabic.
5.6. Variation in Abbreviations
A very common term variation phenomenon in the domain of computers and the Internet is the usage of abbreviations, which are probably more common in English than in Arabic. Abbreviations are prevalent in both specialized and non-specialized domains and occur in both formal and informal contexts. They serve to shorten the linguistic code, thus allowing for more efficient and economic communication for terms and concepts that occur frequently in the discourse of a particular domain. Thus, abbreviations are mostly introduced for terms longer than two words. However, some are introduced for one-word terms, such as اللاإداري allaïdary non-administrative.
Abbreviated forms most often manifest themselves as initialisms and acronyms. While an initialism is formed from the initial letters in a compound term, like PC for personal computer and CD for compact disc, an acronym is a term formed from the initial letters and is pronounced as a word, such as RAM for 'random access memory'. Many abbreviated forms are more common than their full forms. For instance, the full form of HTML (Hypertext Markup Language) could be considered the marked form in the domain of computers and the Internet, as the HTML abbreviation is much more common than its full form. In the case of RAM (Random Access Memory), the full form is so infrequent that many users do not realize that RAM is an abbreviation, thus it becomes a new independent term. The domain of computers and the Internet offers a wealth of abbreviations.
Few methods for acronym and abbreviation formation in Arabic have been developed until recently, a fact that has attracted considerable attention (Spasic el al., 2003, p. 245), especially in scientific and technical domains. Thus there are no strict rules for creating and defining acronyms and abbreviations. In Arabic, as noted above, abbreviation is not as common as in English, since the language structure does not encourage abbreviation (Abu-Absi, 345). In English, abbreviation usually consists of the first letters taken from every word in the term. If we apply this method to Arabic, it would be difficult to form an acceptable abbreviation due to the cursive nature of Arabic script (unlike English, words in Arabic cannot be divided) as well as the complicated sound system and derivation. The results would be as in Table 7.
If we want to read one of the Arabic abbreviations in Table 7—for example, (ل ن ن) lam nun nun 'HTTP,' which is an abbreviation for 'لغة نقل النص' lughat naql alnas hypertext transfer protocol—the reading would be 'lam nun nun,' because the structure for pronouncing one Arabic letter consists of more than three sounds (Lam CVC, noon CVC and non CVC). Thus it is difficult to form abbreviations depending on these sound conditions. For that reason, abbreviations are not commonly used in Arabic and are not usually accepted by Arabic linguists. Consequently, many terminological abbreviations in the two corpora are in fact English or French abbreviations that have been taken over into Arabic as is without applying any formation strategy.
The tendency in the study corpora is either to use the full form of the term without applying the phenomenon of abbreviation or to use the foreign abbreviation in Latin characters without rendering the form in Arabic script, as can be seen in Figure 4. The latter strategy would pose difficulties in understanding the meaning of the abbreviation for users who are not domain specialists and thus are not familiar with that foreign-language abbreviation.
The screenshot (Figure 4) has been taken from C1. As can be seen, English abbreviations such as CPU Central Processing Unit), RAM (Random Access Memory) and MB RAM (Megabyte of Random Access Memory) were used in their original alphabet, without any attempt to find and use their Arabic equivalents or even translate the concepts into Arabic.
Statistics in Table 8 indicate that rendering foreign abbreviations into their complete Arabic translated forms is an important strategy in Arabic term formation. The table shows that terms such as بروتوكول نقل النص التشعبي hypertext transfer protocol, لغة توصيف النص التشعبي Hypertext Markup Language, وحدة المعالجة المركزية central processing unit and شبكة خاصة virtual private network were found in C1 and C2 in their full Arabic equivalents with various frequencies (13, 39, 25 and 45 respectively), immediately followed by their foreign language abbreviations.
The use of the full term in Arabic, however, makes multi-word terms look like ordinary words. The use of capital letters in English abbreviated terms, such as HTTP, HTML, CPU and VPN, indicates the special status of these forms as scientific or technical multi-word abbreviated terms. This distinctive feature, however, disappears in Arabic due to the fact that there is no capitalization in Arabic. Because of this and the complexity of using Arabic abbreviations, writers regularly use foreign language abbreviations instead of their full-form equivalents in Arabic. The data indicates that the use of foreign abbreviations is greater than that of full forms in the two corpora. Table 9 shows the foreign abbreviated terms detected in C1 and C2.
A comparison of the results in Table 8 and Table 9 shows that there is a tendency in Arabic to use foreign abbreviations instead of their Arabic equivalents, either abbreviated or the full forms. The statistics in the two tables indicate that the abbreviation HTML, which has the highest frequency in the two corpora, was used 68 times in C1 in 3 texts and 57 times in C2 in 7 texts, whereas its full Arabic equivalent لغة توصيف النص التشعبي was used 39 times in 2 texts. Similarly, the abbreviation CPU was used 47 times in 7 texts in C1 and 16 times in 3 texts in C2, while its full Arabic equivalent وحدة المعالجة المركزية was used 25 times in 3 texts only. The higher frequency of the foreign abbreviations in Table 9 indicates that although full forms of Arabic abbreviations are regularly used for certain abbreviations for which an Arabic equivalent is available, as in the case in Table 8, foreign abbreviations are still preferred.
6. Conclusion
The influence of English and French on Arabic terminology has been very significant. Many elements form these two languages have been involved in Arabic terminology formation and selection. Trends such as modernization, westernization, and globalization that have been gradually invading Arabic culture since the age of colonization brought in a vast number of foreign terms. This influence has also been more evident in recent years thanks to the development and widespread expansion of communications media as well as extensive travel, trade and tourism. These outside pressures take the form of a strong foreign language hegemony, which results in the tendency of writers and translators, especially in technical fields such as computers and the Internet, simply to adopt terms from English and French. Many of these terms have been assimilated into the Arabic language and are considered by users and even specialists in various technical fields to be standardized terms and thus pose no particular problems.
Borrowing is one of the main means of terminology formation. Many terms have been taken over from English or French, either modifying their usage in Arabic or keeping them as is (with appropriate or regionally influenced transliteration). This wholesale borrowing, which might endanger the aesthetic of the Arabic language, has inspired many linguistic and terminological bodies such as Arabic Language Academy in Cairo to try to put restrictions on this practice, despite its great potential for Arabic terminological and lexical expansion. This restriction, however, has failed to end the practice because of the hegemonic power of foreign languages, mainly English as a global 'lingua franca' of science, technology, business and media. This might mean that foreign terms are more preferred than their Arabic counterparts and that MSA standardized terms are not always publicly accepted. These contradictory attitudes towards Arabic on the one hand and English and French on the other have caused a conflict with Arabic language practice regarding how Arabic should interact with these foreign languages and to what extent this interaction should be allowed. It is crucial, therefore, to create an atmosphere of preferring Arabic (MSA) terminology rather than foreign or even dialectal terms, especially in scientific and technical domains where Arabic domain loss is problematic.
Finally, it remains to be said that English and French influence on Arabic terminology has not yet ended. This influence will increase with the growth of globalization. In the ANAC region in particular and the AW in general and with the tendency toward English and French as a function of modernization, there will be an even greater increase of foreign terms in MSA. Such an influence will continually foster new foreign terms that in many cases fill lacunae and even compete with their established Arabic equivalents. Arabic therefore has no option but to interact with the surrounding languages and gain from them. It will continue to follow this tradition of adopting and foreign terms that have been absorbed through linguistic, cultural, economic, technical and political interaction.
References
Abu-Absi, S. (1986). The modernization of Arabic: Problems and prospects. Anthropological Linguistics,337-348.
Aitsiselmi, F., & Marley, D. (2008). The role and status of the French language in North Africa. Studies in French Applied Linguistics, Ed.Dalila Ayoun.Amsterdam: John Benjamins,
Benrabah, M. (2007). Language-in-education planning in Algeria: Historical development and current issues. Language Policy, 6(2), 225-252.
Freixa, J. (2006). Causes of denominative variation in terminology: A typology proposal. Terminology, 12(1), 51-77.
Gordon, D. C. (1964). North Africa's French legacy, 1954-1962 Center for Middle Eastern Studies of Harvard University.
Holt, M. (1994). Algeria: Language, nation and state. Arabic Sociolinguistics: Issues and Perspectives, 25-41.
Maghur, A. (2010). "Highly-Skilled Migration (Libya): Legal Aspects." European University Institute 31.
ISO 12620. (2009). "Computer Applications in Terminology – Data Categories – Specification of Data Categories and Management of a Data Category Registry for Language Resources". International Organization for Standardization, Geneva, Switzerland.
Jarrar, S. A., & Massialas, B. G. (1992). Arab republic of Egypt. International Handbook of Educational Reform, 149-167.
Roberts, A., Al-Sulaiti, L., & Atwell, E. (2006). aConCorde: Towards an open-source, extendable concordancer for Arabic. Corpora, 1(1), 39-60.
Schaub, M. (2000). English in the Arab republic of Egypt. World Englishes, 19(2), 225-238.
Spasic, I., Nenadic, G., Manios, K., & Ananiadou, S. (2003). An integrated term-based corpus query system. Proceedings of the Tenth Conference on European Chapter of the Association for Computational Linguistics-Volume 1,243-250.
Talmoudi, F. (1984). The diglossic situation in North Africa: A study of classical Arabic-dialectal Arabic diglossia with sample text in" mixed Arabic" Acta Universitatis Gothoburgensis.
Tignor, R. L. (2011). Egypt: A short history (new in paper) Princeton University Press.
Van Mol, M. (2003). Variation in modern standard Arabic in radio news broadcasts: A synchronic descriptive investigation into the use of complementary particles Peeters Pub & Booksellers.
Table 1
Examples of orthographic variation in the two corpora
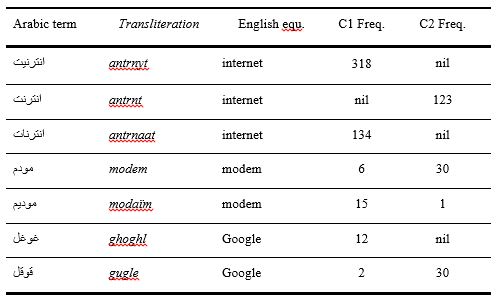
Table 2
Lexical variations among Arabic countries
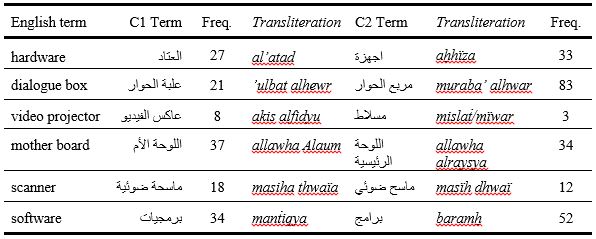
Table 3
Gender variation
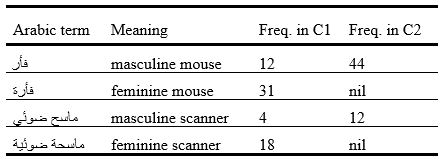
Table 4
High-frequency borrowed terms in the two corpora
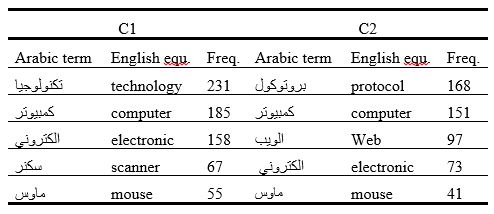
Table 5
Borrowing from different sources

Table 6
Loans from different linguistic sources
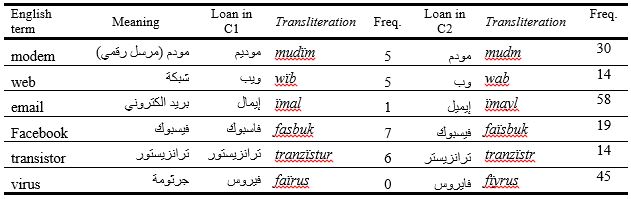
Table 7
Complex Arabic abbreviation
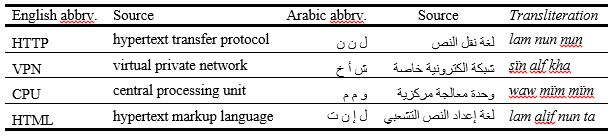
Table 8
Use of full forms of abbreviations in Arabic texts
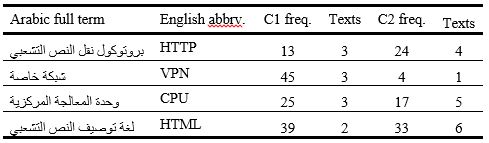
Table 9
Foreign language abbreviations
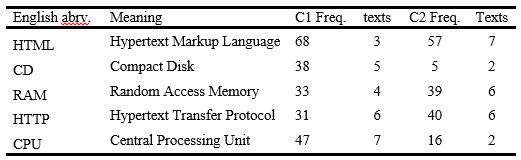
Figure 1. Word list before the generation of function words stop list
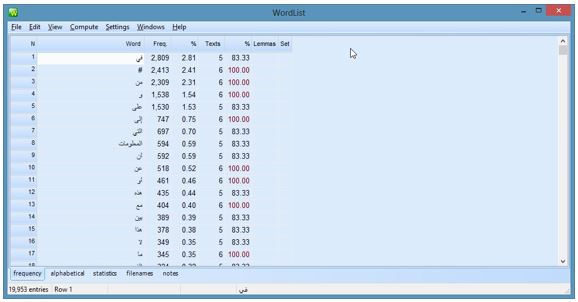
Figure 2. Lemmatization of different inflectional words
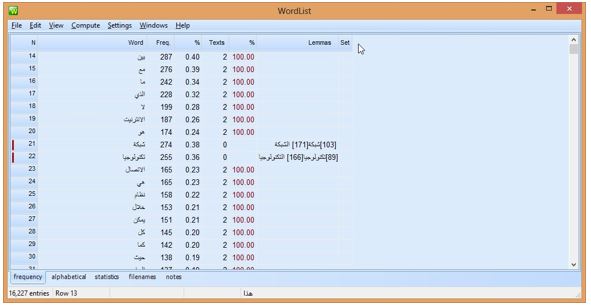
Figure 3. Arabic concordance using WST
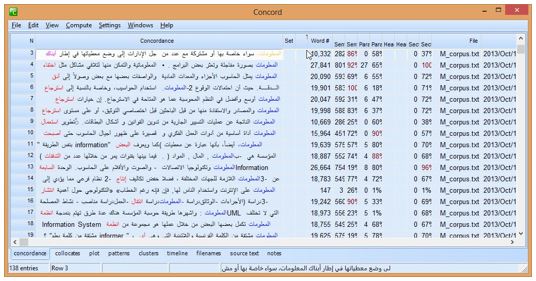
Figure 4. The use of foreign-language abbreviations in Arabic texts

Appendices
A: Stop List of Arabic Words and Their English Equivalents
B: Corpus One Term List
C: Corpus Two Term list
July 2016 Issue
About Fawzi Younis Hamed

Fawzi Younis Hamed received his PhD in Translation Studies from Kent State University, Kent Ohio. His research interest is focused on language planning, terminology planning and policy, terminology standardization, terminology management and corpus terminology. In addition to teaching, Fawzi is currently working as a freelance English/Arabic translator translating different types of texts in various genres including, but not limited to, IT, computer science and literature. He currently lives in Ohio, USA.
Log in